
Estás leyendo la publicación: Alibaba AI Research propone Composer: un modelo de difusión controlable grande (5 mil millones de parámetros) entrenado en miles de millones de (texto, imagen) pares
Hoy en día, los modelos de imagen generativa basados en texto son capaces de crear una amplia gama de imágenes fotorrealistas. Muchos esfuerzos recientes han ampliado los modelos de texto a imagen para lograr aún más la generación personalizada agregando condiciones como mapas de segmentación, gráficos de escena, dibujos, mapas de profundidad y máscaras de pintura interna o ajustando los modelos preentrenados en una pequeña cantidad de datos específicos del tema. . Sin embargo, cuando se trata de aplicar estos modelos para aplicaciones del mundo real, los diseñadores aún necesitan más control sobre ellos. Por ejemplo, es típico en los proyectos de diseño del mundo real que los modelos generativos necesiten ayuda para producir imágenes de manera confiable con demandas simultáneas de semántica, forma, estilo y color.
Investigadores de Alibaba China presentan Composer. Es un gran modelo de difusión controlable (5 mil millones de parámetros) entrenado en miles de millones de pares (texto, imagen). Sostienen que la composicionalidad, en lugar del mero condicionamiento, es el secreto para controlar la formación de imágenes. Este último introduce muchas combinaciones posibles, que pueden ampliar drásticamente el espacio de control. Ideas similares se investigan en las disciplinas del lenguaje y la comprensión de escenas. En estos campos, la composicionalidad se denomina generalización composicional, la capacidad de reconocer o crear un número finito de combinaciones únicas a partir de un número limitado de componentes disponibles. Partiendo del concepto mencionado anteriormente, aportan a Composer en este trabajo una implementación de modelos generativos compositivos. Se refieren a modelos generativos que pueden volver a ensamblar sin problemas elementos visuales para crear nuevas imágenes como modelos generativos de composición. Utilizan un modelo de difusión multicondicional con una red troncal UNet para implementar Composer. Cada iteración de entrenamiento de Composer tiene dos fases: la fase de descomposición, en la que se utilizan algoritmos de visión artificial o modelos previamente entrenados para dividir lotes de imágenes en representaciones individuales, y la fase de composición, en la que Composer se optimiza para reconstruir las imágenes a partir de los subconjuntos de representación.
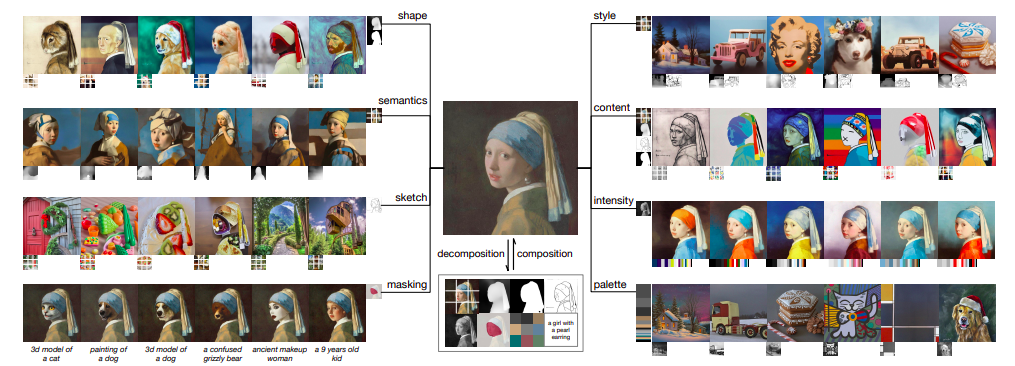
Los compositores pueden decodificar imágenes únicas a partir de combinaciones invisibles de representaciones que pueden provenir de múltiples fuentes y pueden ser incompatibles entre sí mientras que simplemente han sido entrenados con un propósito de reconstrucción. Composer es sorprendentemente eficaz a pesar de su simplicidad conceptual y facilidad de uso, lo que permite fomentar el rendimiento en tareas de manipulación y generación de imágenes convencionales e inexploradas anteriormente, como, entre otras, generación de texto a imagen, generación de imágenes condicionales multimodales, transferencia de estilo , transferencia de poses, traducción de imágenes, prueba virtual, interpolación y variación de imágenes desde varias direcciones, reconfiguración de imágenes modificando bocetos, traducción de imágenes dependientes y traducción de imágenes.
Además, Composer puede limitar la región editable a un área especificada por el usuario para todas las operaciones anteriores, lo que es más flexible que la operación de pintura interna convencional, al mismo tiempo que evita la modificación de píxeles fuera de esta región mediante la introducción de una representación ortogonal de enmascaramiento. A pesar de haberse sometido a una formación multitarea, Composer obtiene un FID de disparo cero de 9,2 en la síntesis de texto a imagen en el conjunto de datos COCO mientras utiliza el subtítulo como criterio, lo que demuestra su capacidad para ofrecer excelentes resultados. Su paradigma de descomposición-composición indica que el espacio de control de los modelos generativos puede aumentar considerablemente cuando las condiciones son componibles en lugar de individuos empleados. En consecuencia, una amplia gama de tareas generativas convencionales se pueden reformular utilizando su arquitectura Composer, y se revelan capacidades generativas hasta ahora no reconocidas, lo que inspira más estudios sobre diversas técnicas de descomposición que podrían lograr una mayor capacidad de control. Además, basándose en una guía bidireccional y sin clasificador, demuestran muchos enfoques para emplear Composer para diferentes tareas de producción y alteración de imágenes, proporcionando referencias útiles para estudios posteriores. Antes de poner el trabajo a disposición del público, planean examinar cuidadosamente cómo Composer puede reducir el peligro de abuso y tal vez proporcionar una versión filtrada.

