
Estás leyendo la publicación: Investigadores de la Universidad de Oxford proponen un marco de aprendizaje automático llamado ‘TriSegNet’ basado en el aprendizaje de funciones de vista triple para la segmentación de imágenes médicas
El rendimiento potencial del aprendizaje profundo para imágenes médicas depende no solo del diseño de la arquitectura de la red, sino también de la disponibilidad de una cantidad suficiente de datos de alta calidad anotados manualmente, que es difícil de conseguir. Dos técnicas para el aprendizaje semisupervisado que han recibido mucha atención son el co-entrenamiento y el auto-entrenamiento. Un modelo se inicializa inicialmente con datos etiquetados durante el autoentrenamiento. Luego, el modelo crea máscaras ficticias para los datos sin etiquetar. El modelo se reentrena ampliando sus datos de entrenamiento y se establece un criterio para elegir pseudomáscaras.
El co-entrenamiento profundo se presentó inicialmente como una solución al problema de las “redes neuronales colapsadas”, que impide el aprendizaje de funciones de vista múltiple cuando dos modelos se entrenan en el mismo conjunto de datos porque inevitablemente se volverán similares. Al aumentar la cantidad de datos de entrenamiento, el entrenamiento conjunto generalmente se usa para entrenar dos modelos distintos con dos puntos de vista. Se crearon métodos como el difuminado de salida, el aumento de diversidad y el abandono para la edición de pseudoetiquetas para disminuir el impacto.
El componente crítico del enfoque es el desarrollo simultáneo de varias (por ejemplo, tres) perspectivas de datos distintas y los parámetros aprendidos relacionados en varios modelos. Permite que cada modelo mejore las contribuciones de los demás al proceso de aprendizaje. Además, no procesan el mismo conjunto de datos; en cambio, eligen subconjuntos dispares de datos cuidadosamente construidos y extraen lo que pueden de cada uno. También se sugiere utilizar un método de aprendizaje semisupervisado de co-entrenamiento multivista para la clasificación, aunque para un problema de clasificación más que para la segmentación semántica.
La predicción detallada de la máscara requiere un método completamente nuevo. Para entrenar el tercer componente CNN, las pseudoetiquetas se generan desde cero en pasos intermedios eligiendo entre la salida de dos componentes CNN separados. La estimación de confianza difiere del enfoque consciente de la incertidumbre en que el marco triple elige las pseudoetiquetas por las que los diversos modelos de componentes han ‘votado’ y en las que han mostrado una alta confianza. Además, demuestran cómo cuantificar cómo esto afecta la confianza general del marco.
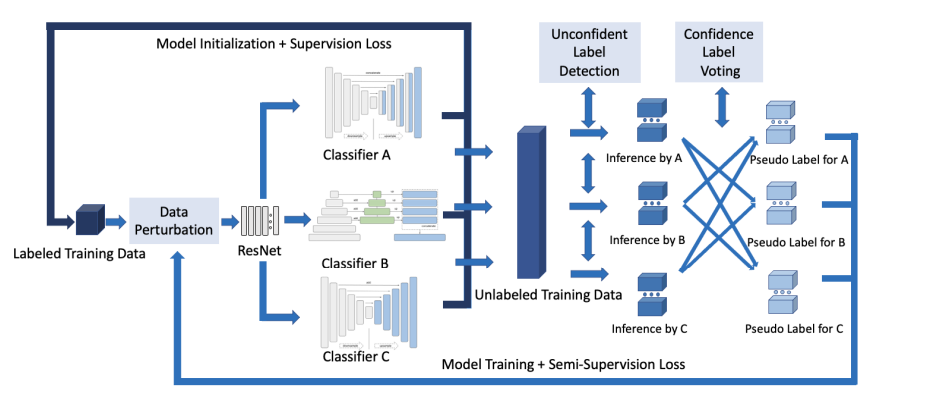
El siguiente paso no emplea pseudo-etiquetas con un nivel de confianza suficiente. La etapa de entrenamiento determina qué tan bajo debe ser ese nivel de confianza; cuanto más avanzado sea el proceso de formación, más seguro debería ser el marco. Como resultado, la cantidad de fotos disponibles para entrenamiento crece gradualmente. La siguiente figura muestra la estructura de la red de aprendizaje de características de triple vista para la segmentación semántica de imágenes médicas (TriSegNet).
 Fuente: https://arxiv.org/pdf/2208.06303v1.pdf
Fuente: https://arxiv.org/pdf/2208.06303v1.pdfLa expresión de características de los datos sin anotar se mejora mediante la edición de etiquetas. Incluye detección de etiquetas no seguras y votación de etiquetas de confianza basadas en una estimación de confianza. La perturbación aleatoria de datos se utiliza para la regularización en cada uno de los tres puntos de vista del aprendizaje de características. Los tres clasificadores de nivel de píxel de aprendizaje de características de alto nivel A, B y C utilizan un ResNet entrenado previamente como un módulo de aprendizaje de características de bajo nivel. La inicialización de la arquitectura y los parámetros se crean por separado para el aprendizaje de triple vista. A, B y C utilizan un codificador-decodificador.
Modelan completamente las dependencias de largo alcance, el tamaño de la variación de la expresión de las características, modelan las conexiones de salto, eluden la información espacial y procesan mapas de características de varias escalas para comunicar suficiente información semántica. ResNet puede extraer características de bajo nivel de forma general debido al módulo de aprendizaje de características de bajo nivel, que sigue el modelo, y las tres vistas del clasificador. En el proceso semisupervisado, A, B y C no solo extraen características, sino que también votan, crean pseudoetiquetas y, en general, se benefician mutuamente.
Este artículo está escrito como un artículo de resumen de investigación por el personal de Marktechpost basado en el trabajo de investigación ‘Aprendizaje de funciones de vista triple para la segmentación de imágenes médicas‘. Todo el crédito de esta investigación es para los investigadores de este proyecto. Revisar la papel y enlace github.
Por favor no olvides unirte Nuestro subreddit de ML
Echa un vistazo a https://aitoolsclub.com para encontrar 100 de Cool AI Tools

