
Şu yazıyı okuyorsunuz: Yeni bir yapay zeka (AI) araştırma yaklaşımı, ipucuna dayalı bağlam içi öğrenmeyi istatistiksel açıdan bir algoritma öğrenme sorunu olarak sunuyor
Bağlamda öğrenme Bu yeni bir paradigmadır; büyük dil modeli (LLM), bir test örneğini ve bazı eğitim örneklerini girdi olarak gözlemler ve parametrelerinde herhangi bir güncelleme yapmadan çıktının kodunu doğrudan çözer. Bu örtülü eğitim, ağırlıkların örneklere göre değiştirildiği normal eğitimle çelişir.
İşte bağlam içinde öğrenmenin neden faydalı olacağı sorusu geliyor. Modellemek istediğiniz iki regresyon göreviniz olduğunu varsayabilirsiniz ancak tek sınırlama, her iki görev için yalnızca bir model kullanabilmenizdir. Burada, regresyon algoritmalarını görev bazında öğrenebileceğiniz için bağlam içi öğrenme faydalıdır; bu, modelin farklı girdi kümeleri için ayrı uygun regresyonlar kullanacağı anlamına gelir.
Kağıt üzerinde “Algoritma olarak dönüştürücüler: bağlamda öğrenmede modellerin genelleştirilmesi ve örtülü seçimi” bağlamda öğrenme problemini bir algoritma öğrenme problemi olarak resmileştirdiler. Çıkarım anında başka bir hedef algoritmayı uygulamak için eğitim yoluyla uzmanlaşabilecek bir öğrenme algoritması olarak bir transformatör kullandılar. Bu makalede, dönüştürücüler aracılığıyla öğrenmenin istatistiksel yönlerini bağlam içinde araştırdılar ve teorik tahminleri doğrulamak için sayısal değerlendirmeler yaptılar.
Bu çalışmada, iki senaryoyu araştırmışlardır; ilkinde uyarılar bir dizi iid çifti (giriş, etiket) tarafından oluşturulurken, diğerinde dizi dinamik bir sistemin yörüngesidir (bir sonraki durum önceki duruma bağlıdır). durum : Xm+1 = f(xmetre) + gürültü).
Şimdi şu soru geliyor: Böyle bir modeli nasıl eğitiriz?
ICL’in oluşum aşamasında, T görevler bir veri dağıtımıyla ilişkilidir {DT}t=1T. Eğitim dizilerini bağımsız olarak örneklerler EvetT her göreve karşılık gelen dağıtım. Daha sonra aşağıdakilerin bir alt dizisini geçerler: EvetT ve bir değer X dizinin EvetT hakkında bir tahminde bulunmak X. İşte meta-öğrenme çerçevesi gibi. Tahminden sonra kaybı en aza indiririz. ICL eğitiminin arkasındaki sezgi, eldeki göreve uyacak en uygun algoritmayı bulmak olarak yorumlanabilir.
Daha sonra ICL’de genelleme limitlerini elde etmek için algoritma kararlılık literatüründen bazı kararlılık koşullarını ödünç aldılar. ICL’de göstergeye ilişkin bir eğitim örneği, o noktadan itibaren algoritmaların gelecekteki kararlarını etkiler. Bu girdi bozukluklarıyla baş edebilmek için girdiye bazı koşullar getirmeleri gerekiyordu. Okuyabilirsin [paper] daha fazla ayrıntı için. Şekil 7 öğrenme algoritmasının kararlılığını değerlendirmek için yapılan deneylerin sonuçlarını gösterir (burada Transformer).

RMTL çoklu görev öğrenmedeki risktir (~hata). Türetilmiş limitin fikirlerinden biri, ICL’nin genelleme hatasının örneklem büyüklüğünün arttırılmasıyla ortadan kaldırılabileceğidir. kuzey veya dizi sayısı METRE görev başına Aynı sonuçlar kararlı dinamik sistemlere de genişletilebilir.
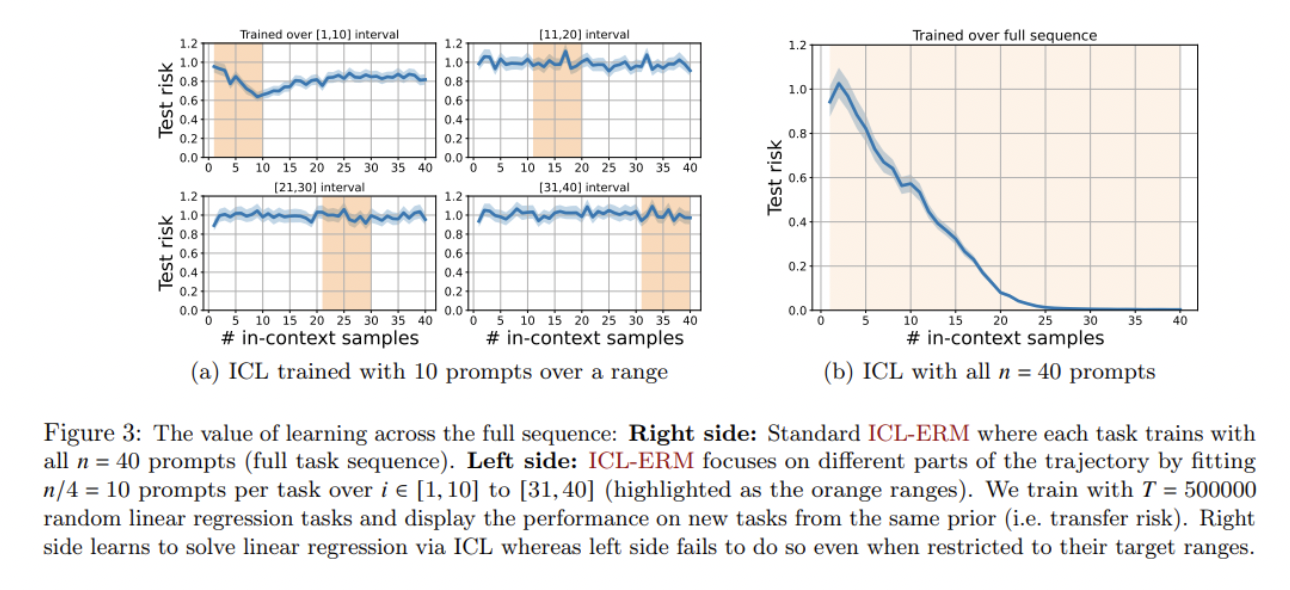
Şimdi bu sınırların sayısal değerlendirmeler kullanılarak doğrulanmasına bakalım.
GPT-2 mimarisi Tüm deneylerde 12 katman, 8 dikkat başlığı ve 256 boyutlu gömme içeren bir sistem kullanılmıştır. Deneyler regresyon ve doğrusal dinamikler üzerinde gerçekleştirilir.
- Doğrusal regresyon: Her iki şekilde de (2(a) ve 2(b)) bağlam içi öğrenme sonuçları (kırmızı), en küçük kareler sonuçlarından (yeşil) daha iyi performans gösterir ve optimum ağırlıklı/sırt çözümüyle (siyah noktalar) mükemmel şekilde hizalanır. ) . Bu da önceki görevlerden öğrenerek transformatörlerin otomatik model seçme kabiliyetine dair kanıt sağlar.
- Kısmen gözlenen dinamik sistemler: Şekiller (2(c) ve 6), sonuçlar bağlamda öğrenmenin neredeyse tüm düzeylerde en küçük kareler sonuçlarından daha iyi performans gösterdiğini göstermektedir. H=1,2,3,4 (burada H, modele alt dizinin uzunluğuna benzer bir girdi oluşturmak için giriş durumu dizisi üzerinde kayan pencerenin boyutudur)
Sonuç olarak, deneysel sonuçların teorik tahminlerle uyumlu olduğunu başarılı bir şekilde gösterdiler. Ve işin gelecekteki yönü açısından, birkaç ilginç soru araştırılmaya değer olacaktır.
(1) Önerilen limitler MTL riski içindir. Bireysel görev sınırları nasıl kontrol edilebilir?
(2) Tamamen gözlemlenen dinamik sistemlerden elde edilen aynı sonuçlar, takviyeli öğrenme gibi daha genel dinamik sistemlere genişletilebilir mi?
(3) Gözlemden, transfer riskinin yalnızca MTL görevlerine ve bunların karmaşıklığına bağlı olduğu ve modelin karmaşıklığından bağımsız olduğu sonucuna varılmıştır, dolayısıyla bu endüktif önyargıyı ve transformatörün ne tür bir algoritma olduğunu karakterize etmek ilginç olacaktır. öğrenme. .
